SAN FRANCISCO, CA / ACCESS Newswire / December 12, 2025 / In the race to build more powerful artificial intelligence systems, one scarce resource has become more valuable than compute itself: high-quality, legally sourced data. A young San Francisco startup, Kled AI, has stepped directly into that void. Founded in May 2025, the company has now raised at a valuation exceeding $100 million as it works to build what it calls the world's first consumer data marketplace - a platform where ordinary people can upload their data and get paid for it, while enterprises gain access to structured datasets used for training next-generation AI models.
The company's approach sits at the intersection of two pressures shaping the AI industry: rising regulatory scrutiny around data provenance, and the growing need for diverse, high-volume datasets that can support multimodal and agentic models. Over the past three months, Kled has begun to attract attention for addressing both sides of the equation.
A Marketplace Built From Early Proof Points
Kled's first version (V1), released earlier this year, served as an experiment: could people meaningfully earn money by contributing their personal data - photos, videos, documents, and day-to-day digital activity? According to the company, the answer was yes. Thousands of early users joined the app and collectively earned hundreds of thousands of dollars in payouts, validating that consumers were willing to participate if the platform provided clear incentives and transparent ownership controls.
But V1 also surfaced the growing pains of a marketplace model. Uploading was slow, duplicate submissions were frequent, and the platform lacked the classification and structuring capabilities needed for enterprise-grade datasets. These constraints informed what would eventually become Kled's full rebuild.
A Rebuilt Platform for an Evolving Industry
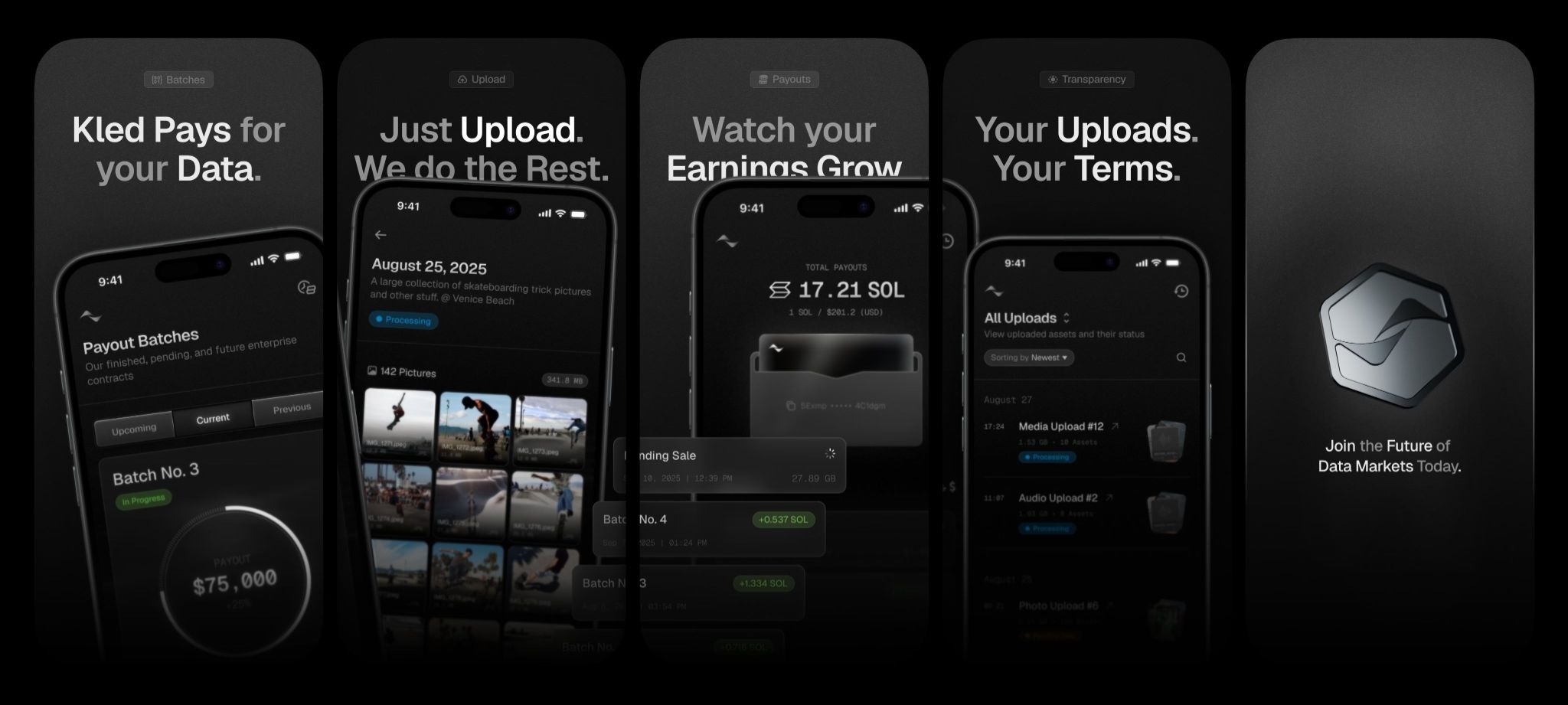
The newly launched V2 platform is at the center of Kled's most recent announcement and the primary driver of investor confidence. The company rebuilt every part of the product - from upload systems to data labeling pipelines - to support higher volumes and more complex enterprise needs.
Uploads are now roughly three times faster, real-time duplicate detection prevents users from padding submissions, and an upgraded classifier automatically labels images and videos with metadata that makes datasets more usable for AI training. The platform also introduces new payout options through mainstream financial services and crypto, and removes the waitlist entirely, opening the marketplace to anyone.
One of the most notable additions is the introduction of "special tasks," structured assignments requested directly by enterprises seeking very specific data types. These can range from capturing videos of everyday household behaviors to photographing infrastructure elements like potholes - the kinds of narrow datasets companies increasingly require but cannot acquire at scale through traditional means.
Research at the Core
Another unexpected development for a company so young is its investment in research. To position itself at the frontier of data science, Kled has begun assembling a team of researchers from Stanford, Duke, MIT, Caltech, and other leading institutions. Their focus includes multimodal dataset architecture, labeling strategies, data diversity modeling, and evaluation frameworks for testing how different forms of user-generated content impact downstream model performance.
This research emphasis is part of a broader shift: as AI systems become more capable, the quality of their training data matters as much as model architecture. Kled appears to be betting that the companies solving tomorrow's AI tasks will need not only large datasets, but datasets with provenance, structure, and context - all of which consumer-contributed data can provide when properly organized.
Enterprise Partnerships and Early Demand
Kled's traction on the enterprise side has grown rapidly. In recent months, the company has signed a range of data licensing partnerships across film, healthcare, robotics, consulting, and finance. These deals include access to large rights-holder libraries, anonymized institutional records, and niche forms of footage - such as drone videos, robotics POV sequences, and real-world behavioral clips - that are increasingly important in training multimodal AI systems.
The company says demand for these datasets has surpassed early expectations, and that enterprises are actively seeking alternatives to scraping, licensing uncertainty, and the rising cost of synthetic augmentation.
A Young Company, An Emerging Category
Kled's $100 million valuation reflects a growing belief among investors that data will become its own marketplace category, distinct from cloud infrastructure or model development. While still early, the company's approach offers a potential blueprint for how consumers might eventually participate in the economics of the AI ecosystem.
Whether Kled can scale both sides of its marketplace - supply from users and demand from enterprises - remains an open question. But its early payouts, rapid user adoption, research investments, and expanding dataset catalog suggest that it has tapped into a structural shift in the AI landscape: one where provenance and participation matter as much as scale.
As the industry confronts a future defined by increasingly powerful models and increasingly scarce high-quality data, Kled represents one of the first attempts to realign how that data is sourced - and who benefits from it.
Media/contact details -
Emma Duong
Emma@kled.ai
(504) 867-9979
https://www.kled.ai/
San Francisco California
SOURCE: Kled.Ai
View the original press release on ACCESS Newswire